
Dossier Stockage : les technologies clés pour 2011
| Sommaire du dossier |
| 1 - Les technologies clés pour 2011 (1ère partie) 2 - Les technologies clés pour 2011 (2nde partie) 3 - Les tendances du stockage pour 2011: les prédictions des analystes 4 - 10 conseils pour la gestion du stockage sur les serveurs virtualisés |
Optimiser le stockage a été l’un des maîtres-mots des deux dernières années et au vu des prédictions d’IDC en matière de croissance des volumes de données dans les entreprises, les administrateurs de stockage peuvent se préparer à poursuivre sur cette voie pour les années à venir. La bonne nouvelle est qu’une large partie des optimisations qu’ils devaient jusqu’alors opérer manuellement est de plus en plus assumée par les baies de stockage elles-mêmes et que de nouvelles technologies devraient se généraliser en 2011 à commencer par la hiérarchisation automatique des données (Automated Tiering), la réduction des données primaires (déduplication et compression).
Pour faire face à la croissance des données non structurées, de nouvelles approches du NAS basée sur le cluster à grande échelle sont aussi en train d’émerger comme l’attestent les rachats en 2009 et 2010 de pionniers tels qu’Ibrix (HP), Isilon (EMC),Exanet (Dell) … Ces approches promettent de pouvoir accroitre la capacité et la performance des NAS linéairement avec les besoins par simple ajout de nœuds additionnels au cluster.
Du côté de la virtualisation et du cloud, plusieurs casse-têtes restent à régler comme celui du choix des protocoles à utiliser. NFS a gagné du terrain en 2010 sur les protocoles blocs et devrait poursuivre sur sa lancée en 2011. La question de la sauvegarde des environnements virtuels reste également un sujet sensible.
Enfin, le cloud storage commence à émerger et devrait aussi être une des tendances à suivre en 2011 (même si nous y reviendrons de façon plus large dans un prochain dossier au printemps).
1. 2011 : Année de la hiérarchisation automatique de données.
La hiérarchisation des données n’est pas une nouveauté. Dans les années 90, une technologie Mainframe comme DFHSM avait déjà introduit des notions de hiérarchisation de données (selon des critères d’âge et de performance). Les données stockées sur disque pouvaient par exemple être migrées sur une librairie de bande externe après une certaine période. En 2004, Nicolas Couraud, à l’époque Directeur du Technology Solution Group d’EMC (aujourd’hui patron de la SSII Newrun), justifiait ainsi l'approche d'IBM : "le HSM faisait de la hiérarchisation de stockage à une époque ou le Gigaoctet était hors de prix en environnement mainframe". La hiérachisation de données modernes s'appuyant largement sur des disques SSD encore très coûteux, on ne peut s'empêcher de faire le parallèle (même si rien ne dit que l'arrivée de SSD abordables ne renverra pas à terme les mécanismes de hiérachisation à la remise...).
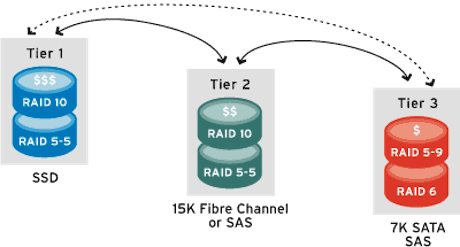 |
| Le concept de la hierarchisation de données expliqué par Compellent |
Dans la pratique, la hiérarchisation de données version 2011 reprend certains principes du HSM mais de façon bien plus sophistiquée et surtout de façon bien plus granulaire. De plus, les mouvements de données restent (pour l'instant) limités à la baie. L’idée est que les systèmes de stockage modernes ont l’intelligence nécessaire pour déplacer automatiquement des blocs de données d’une classe de stockage à une autre en fonction des règles établies par l’administrateur. C’est par exemple le cas des baies Storage Center de Compellent mais également de plusieurs baies IBM (dotées de la fonction easy tiering), des baies Clariion CX4, VNX et Symmetrix d’EMC ou des systèmes de stockages VSP d'Hitachi Data Systems.
Avec la généralisation de la virtualisation, du Thin provisionning et du tiering automatique, il est aujourd’hui possible de constituer des pools de stockage hybrides combinant par exemple un espace de stockage SSD, un espace de disques SAS et un espace de disques SATA. Pour une application typique, un volume sera composé de 5% d’espace disque SSD, de 25% de disques SAS rapides et de 70% de disques SATA et le tiering automatique se chargera du déplacement automatique des données entre ces différentes classes.
 |
| Richard Villars, IDC : "Nous en sommes aux premiers stades de la hiérarchisation de données" |
L’émergence des SSD est une incitation majeure à l’utilisation de la hiérarchisation automatique des données. Un disque SSD coûte environ 10 fois plus cher qu’un disque traditionnel et il est assez difficile pour la plupart des applications de justifier son coût dans le cadre d’un usage statique. Le tiering automatique, en rendant dynamique le positionnement des données assure que la classe de service SSD est utilisée à son plein potentiel. Au passage, cette optimisation permet de réduire le nombre de disques FC dans la baie au profit de plus de disques SATA, ce qui permet d’optimiser les coûts, mais aussi la consommation électrique de la baie. Bref, les bénéfices du tiering sont multiples. Il est à noter que le niveau de granularité dans la gestion des blocs par les mécanismes de tiering varie d’un constructeur à l’autre. Compellent est ainsi capable de gérer des pages de données de 512 Ko, 2Mo et 4 Mo, tandis que la technologie Fast des Clariion procède par bloc de 1Go et que celle des Symmetrix (Fast VP) fonctionne par page de 8Mo. Le Tiering dynamique d’Hitachi fonctionne quant à lui sur des pages de 42 Mo.
A ce jour, les fonctions de hiérarchisation de données ne s’appliquent qu’à l’échelle d’une baie, mais l’on peut envisager qu’elles s’étendront à terme à plusieurs baies. D’ailleurs HDS a annoncé le support du tiering automatique pour les baies tierces depuis son contrôleur virtualisé VSP pour 2011. «Nous en sommes aux premiers stades", explique Richard Villars, vice-président, systèmes de stockage d’IDC. "Il y a deux ans, le Thin provisioning était vu comme une chose risquée. Aujourd’hui c’est une exigence de fait, en particulier dans les environnements virtualisés. Je pense qu’il va en être de même pour la hiérarchisation automatique des données et que l’évolution va se faire sur un cycle similaire au cours des deux prochaines années ".
Aucun commentaire:
Enregistrer un commentaire